

We are going to delve deeper uncovering the hidden patterns in passwords. First of all, we need password datasets / breached lists of once hacked passwords. For our part 2 we will analyze the common password collections from known breaches that can be found in ‘seclists’ libraries.
For the purpose of this article I wrote a number of python scripts for pass dataset analysis, we will be using them throughout our exploration. You can find them here: https://github.com/5u5urrus/PassPatternLab/tree/main
Most Common Character
We will start simple. What is the most common character used in various password breaches?
| 000webhost.txt | Ashley-Madison.txt | rockyou-75.txt | singles.org.txt | hotmail.txt |
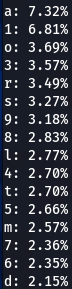 | 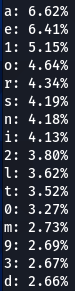 | 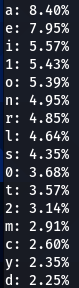 | 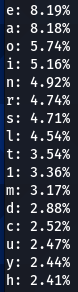 | 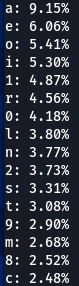 |
Here we have our first finding, character ‘a’ is encountered at the top nearly every time. Followed by ‘e’, ‘1’, ‘o’, ‘i’, ‘r’, ‘s’. Some patterns are exactly the same, like letter ‘d’ being exactly on the 16th position of three (out of five displayed above) word-lists.
Position
How does character positioning influence password patterns? To explore this, I’ve developed a script that identifies the most frequently occurring characters at each specific position within passwords. Let’s examine the findings to see if we can discern any intriguing new patterns.
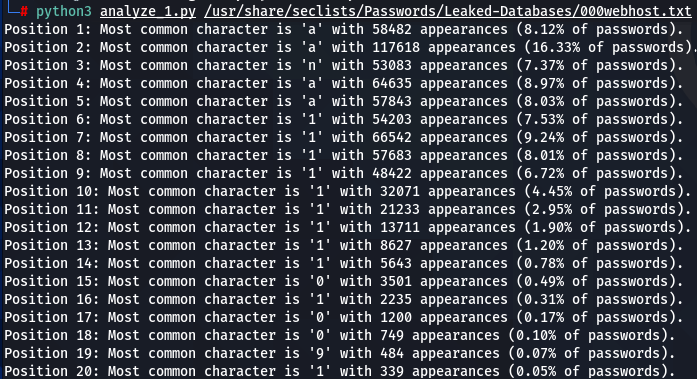
000webhost.txt:
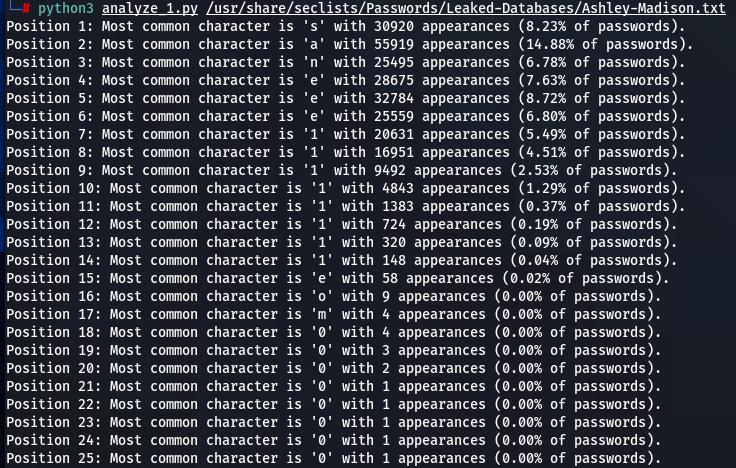
Ashley-Madison.txt:
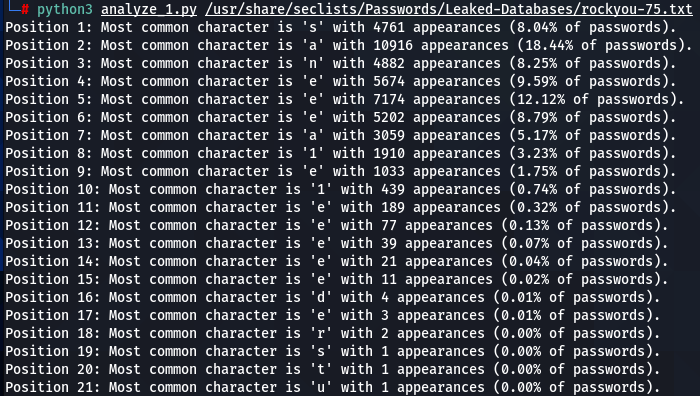
rockyou-75.txt:
singles.org.txt:
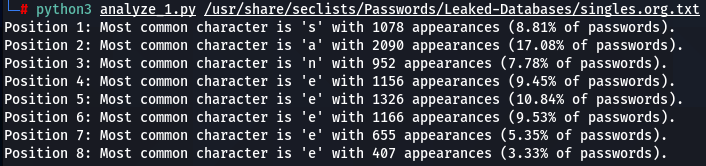
hotmail.txt:
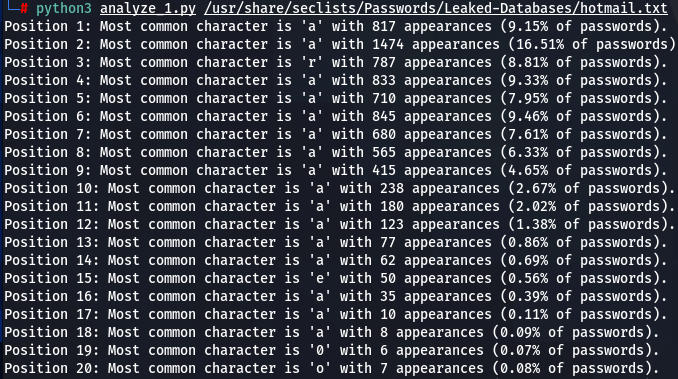
After reviewing the results, I found myself pleasantly surprised by the emerging patterns. Here are some of them:
- While the most common character in passwords is letter ‘a’, and letter ‘s’ being in 5-9th positions, however, it appears that when it comes to the most common occurrences of the first character in passwords – the letter ‘s’ is often at the top, closely followed by ‘a’. Letter ‘s’ is way more common as the first character in passwords. Perhaps most common.
- Here we got an amazing discovery of pattern repeating with striking precision: letter ‘a’ appears to be occurring every time at the second position as the most common character with the highest percentages (around 16-18% of the time). Hence, we can conclude that approximately one out of 5 passwords will have the second character ‘a’. Note that the letter ‘a’ commonly appears in every position, but nowhere as often as the second character of the password.
- In analyzing two of the largest datasets—000webhost.txt and Ashley-Madison.txt, millions of passwords – an interesting trend emerges. Beginning from the 6th or 7th position and continuing through to the 14th, the most commonly encountered character is the number ‘1’. This pattern suggests an increased preference for using numbers, particularly ‘1’, in the mid to later segments of passwords. While earlier positions are dominated by letters, with ‘s’ and ‘a’ being the most frequent, a shift towards numerical characters is observed in the subsequent positions, highlighting a distinct pattern in password composition.
- In an intriguing pattern I found across all five analyzed word-lists, the distribution of frequencies of password characters starts robustly, spikes significantly at the 2nd position, dips at the 3rd, and experiences a slight rise at the 4th position, followed by a gradual decline. This cyclical pattern appeared in all five word-lists I analyzed, amazing; note, how the highest frequency of a most common character consistently occurs with the letter ‘a’ at the 2nd position. This trend also indicates an increasing randomness in character selection as the password lengthens, starting from the 2nd position onwards. Initially, people tend to favor a select few characters, notably ‘a’, ‘s’, and ‘e’, for the early positions in their passwords. However, as they progress to later positions, the choice of characters diversifies, leaning towards a more random selection. The similarity in the character frequency distribution graphs for different wordlists is striking, suggesting a latent mathematical function could be underlying these observed patterns.

Each Character for Each Position
To confirm previous findings and perhaps discover new, lets dive deeper, and analyze characters sorted by the frequency of their occurrences at each position. For that purpose I wrote another python tool to do just that. The screens of the results are below for 000webhost.txt:
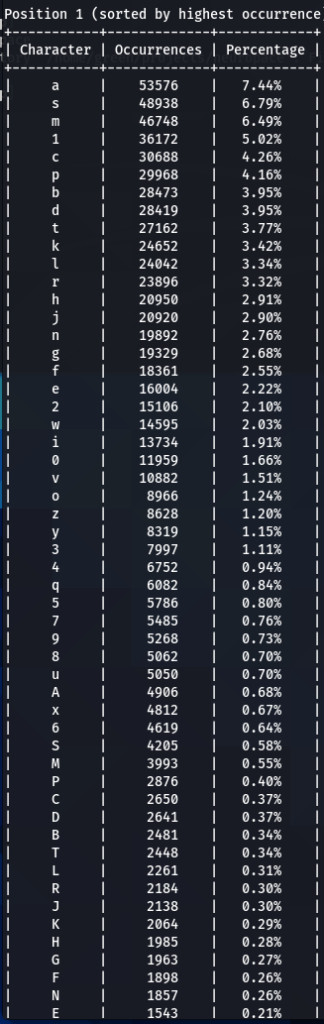
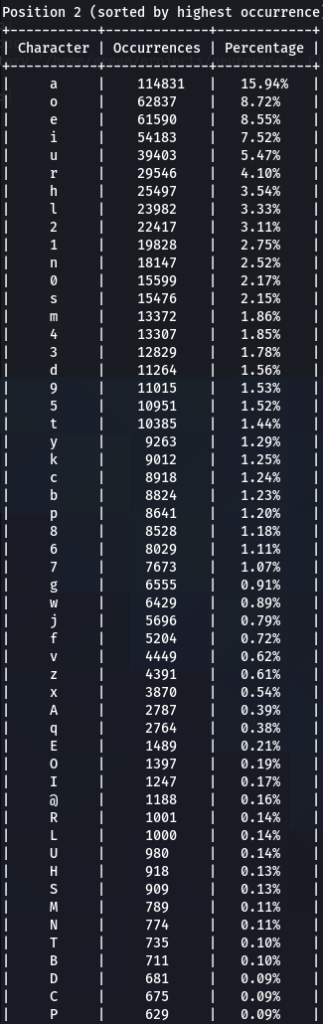
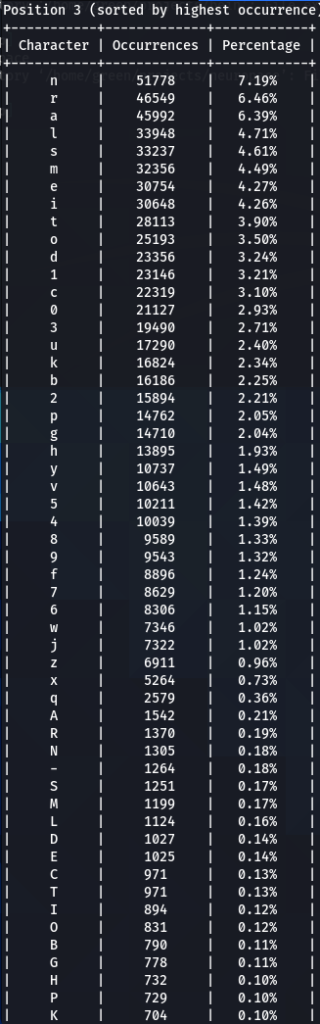
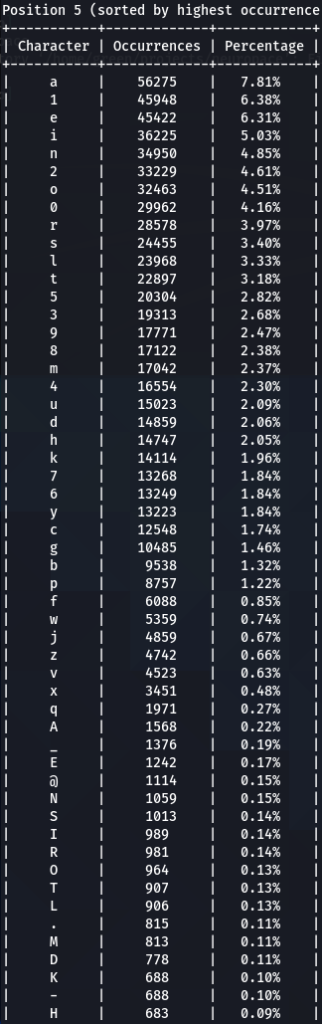
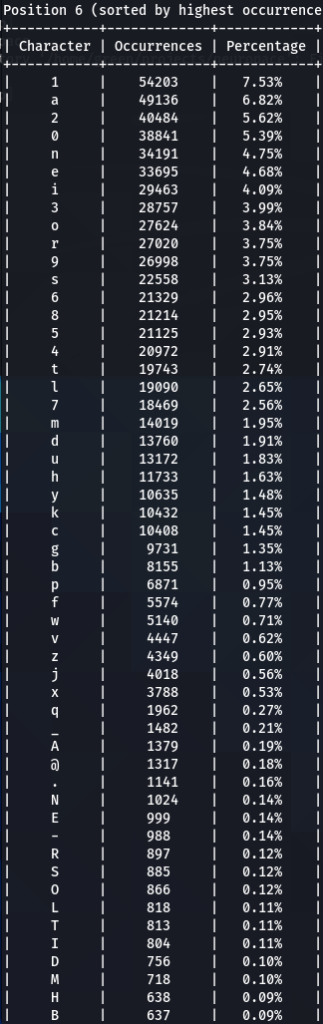
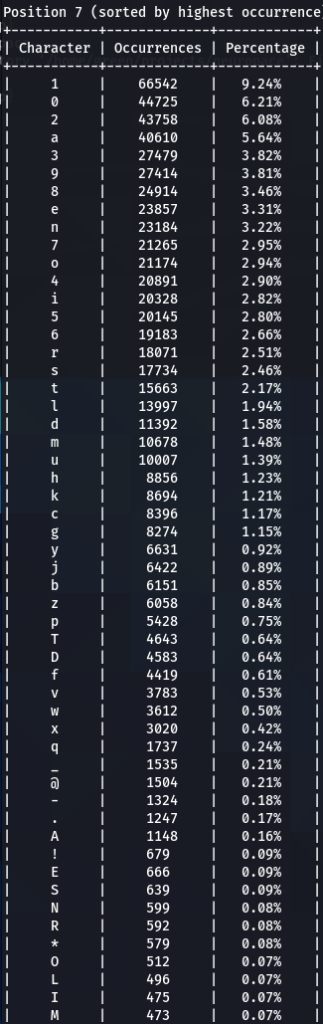
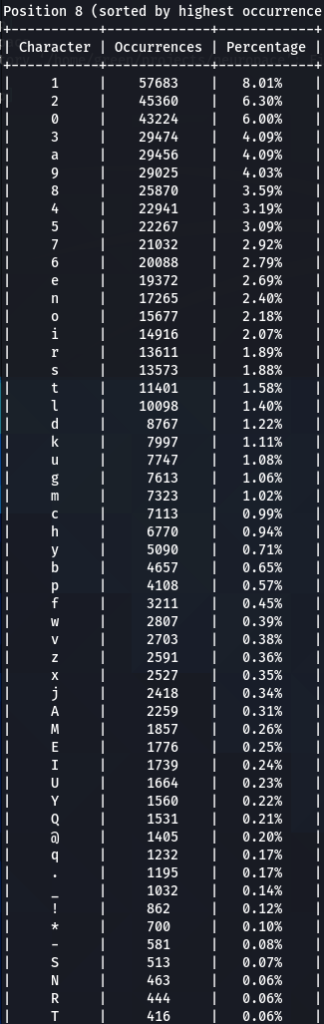
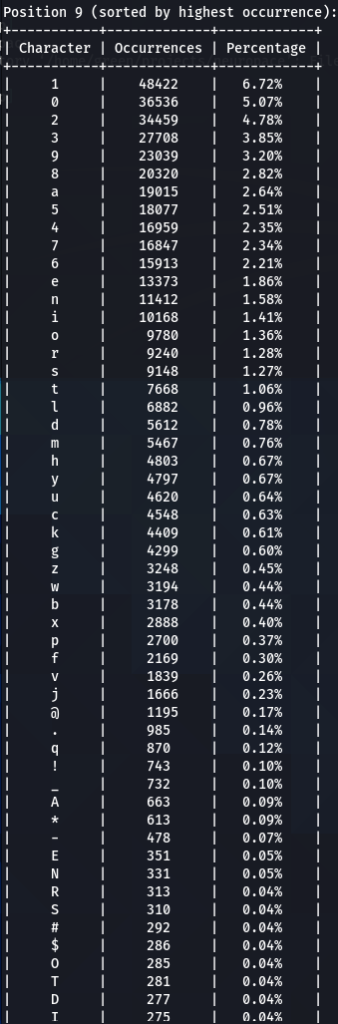
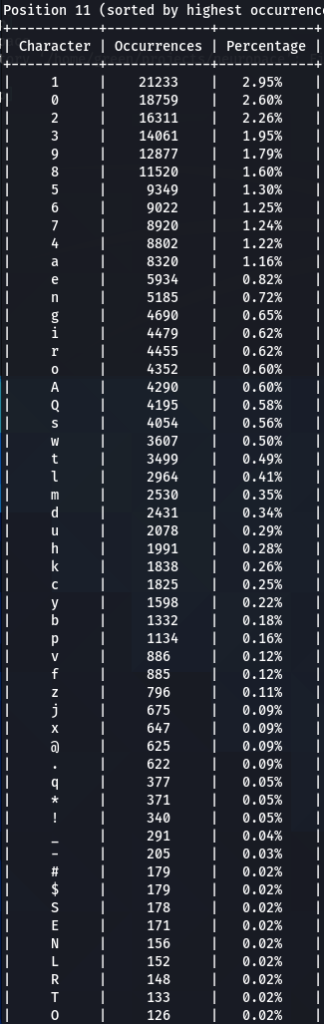
To get the “second opinion”, lets do a similar analysis on Ashley-Madison.txt wordlist:
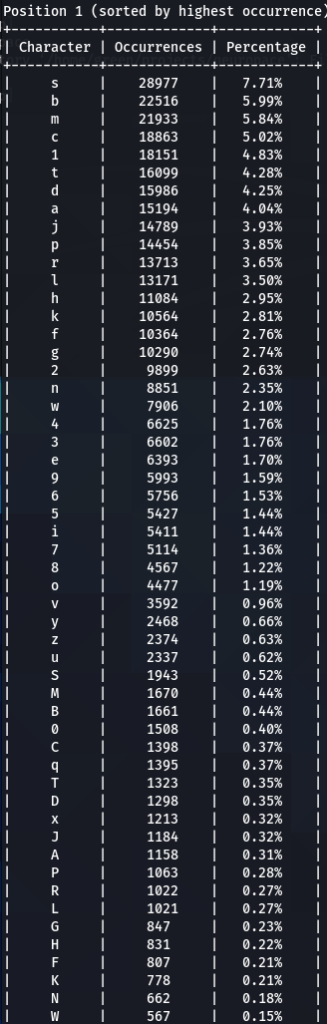
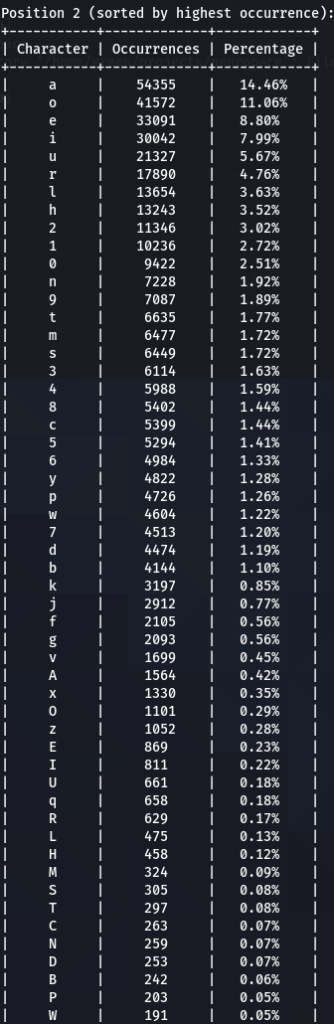
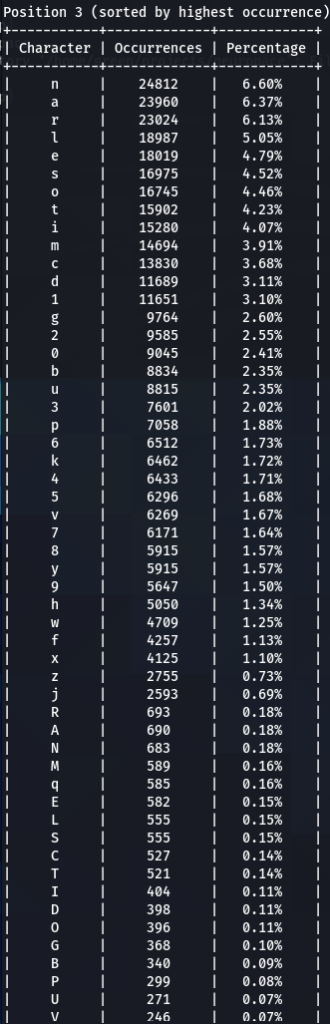
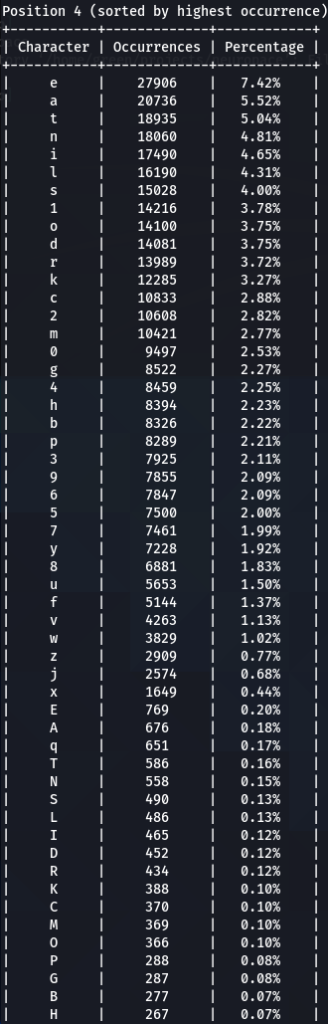
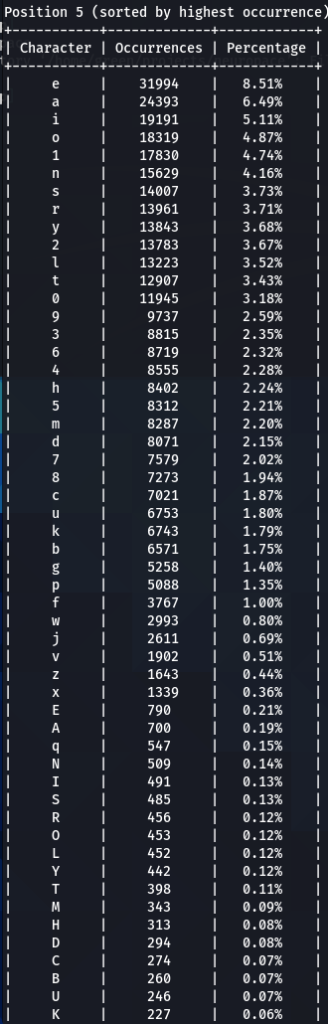
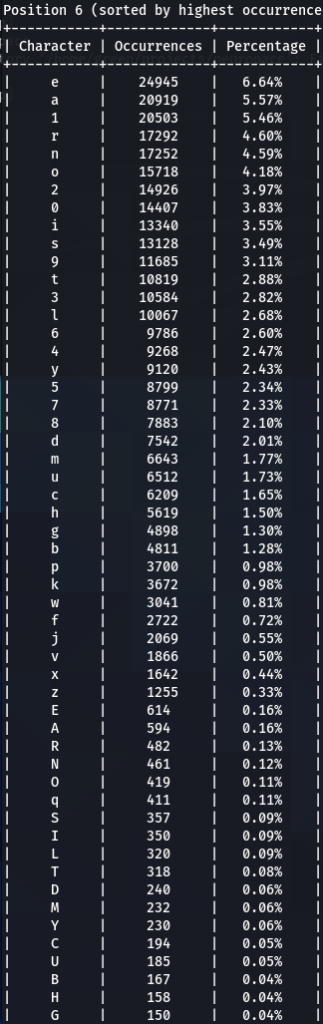
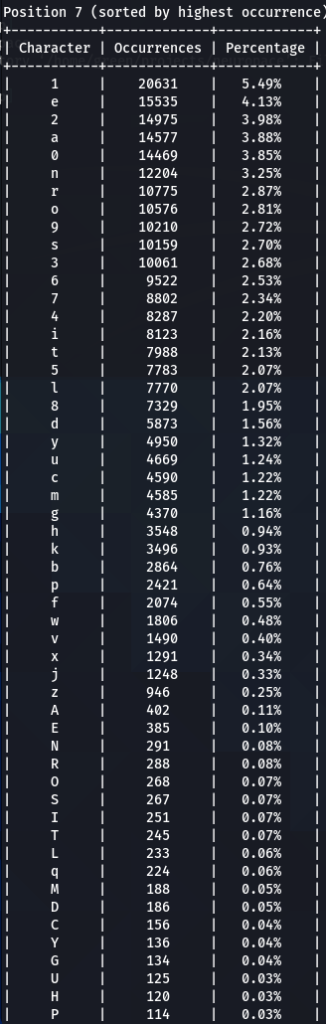
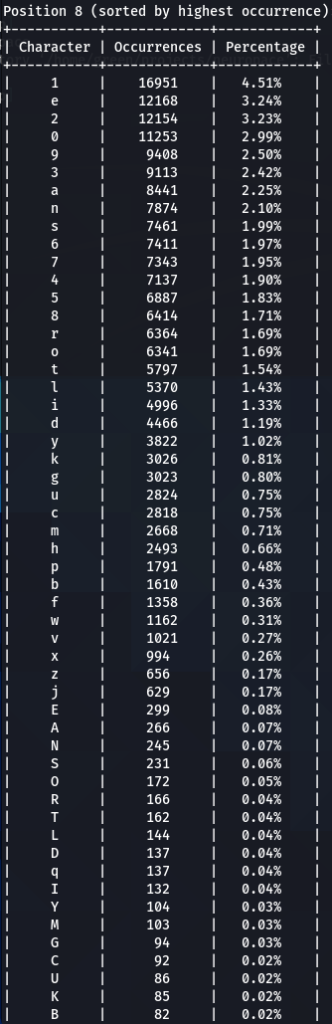
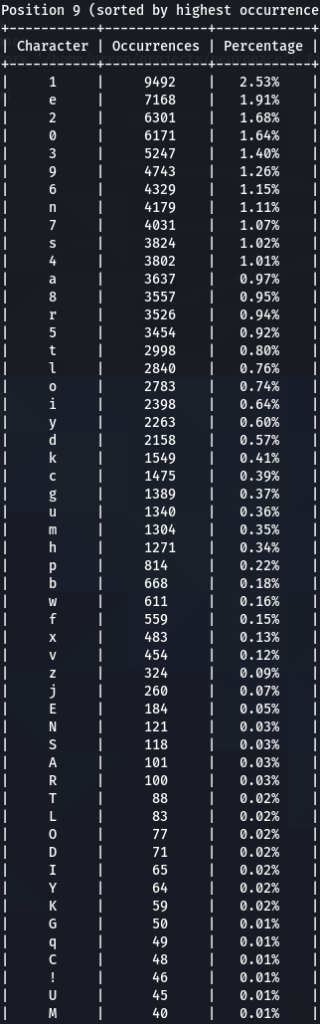
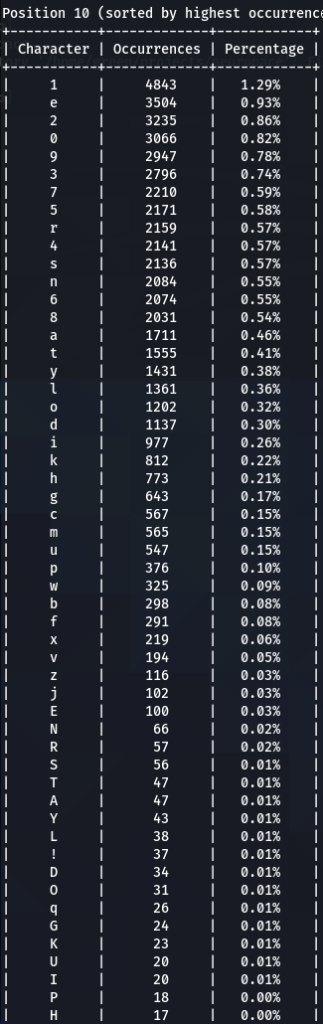
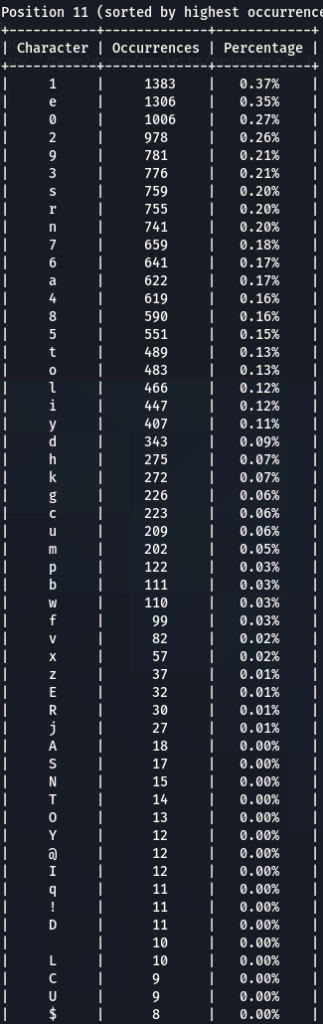
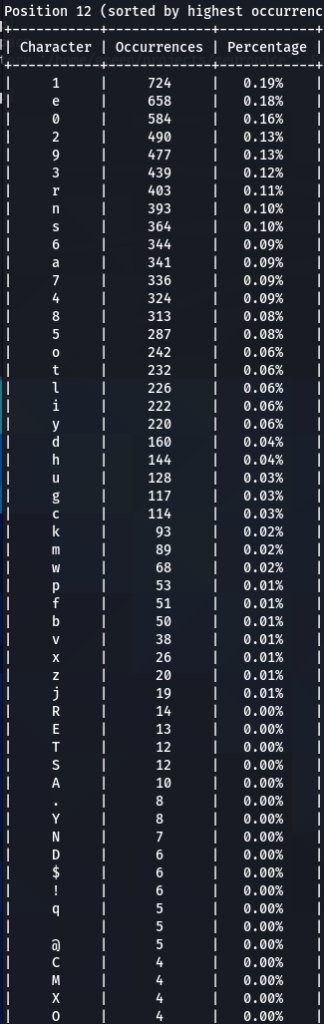
So what can be inferred from this? After watching these, these are the patterns I discovered:
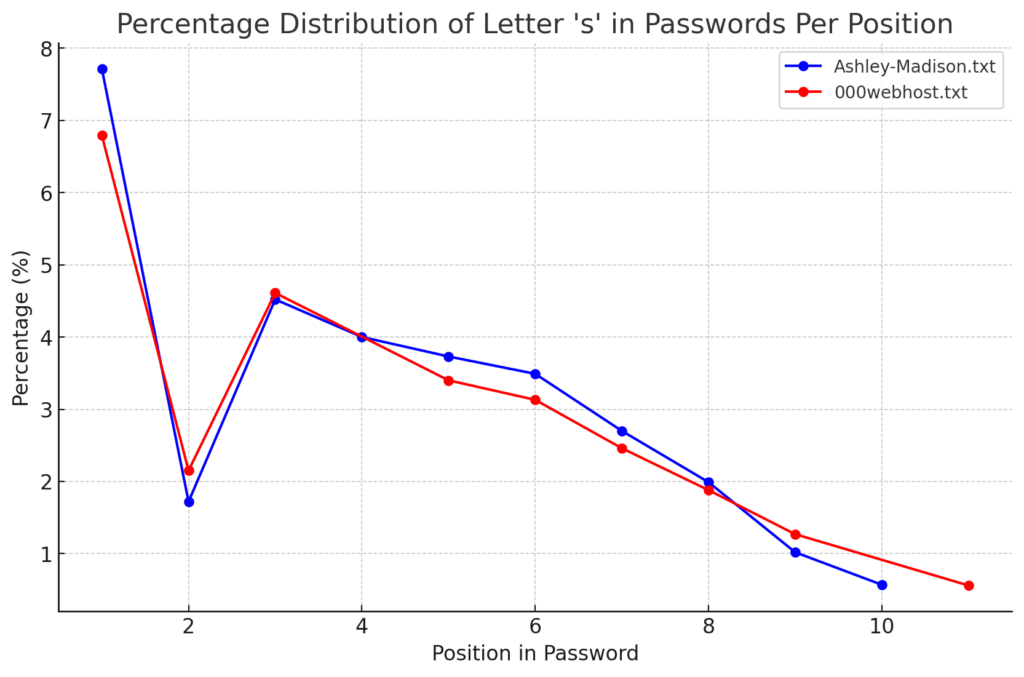
- ‘s’ – the special letter. Look at its distribution – strikingly similar. In both wordlists letter ‘s’ comes at near the top of the first position. Then it sharply drops at the second position (to 13-16th place), and then again jumps to a high position. Below are the graphs for letter ‘s’ frequencies by percentage and ranking in passwords. The percentage graph is near identical for the two datasets. This interesting pattern can be explained by different reasons…like vowels, the keyboard position of letter ‘s’, the frequency of English words, and perhaps other deeper reasons. However, the more general interesting conclusion we arrive is – perhaps, like letter ‘s’, every character has its repeating frequency distributions in passwords? In that case, can’t our bruteforcing tools be written in a much more adequate way, accounting to those probabilities and percentages?
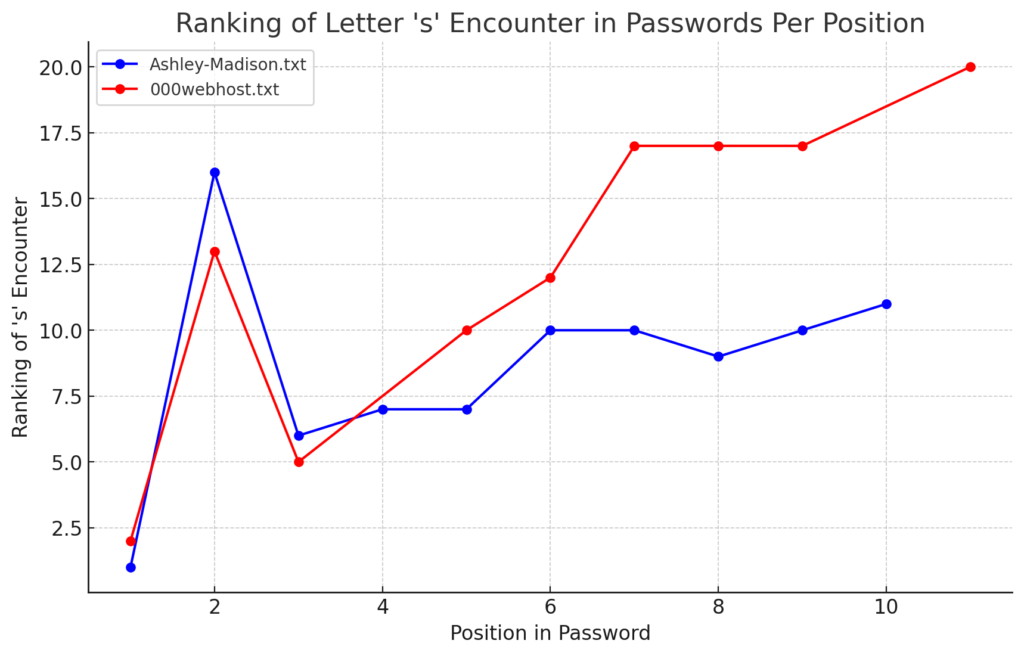
- Note how frequency of numbers sharply increase after 6th 7th positions, taking the lead in rate of occurrences. If before we mostly usually encountered letters, after 6-7th positions numbers are more likely to appear in passwords.
- Not all numbers are popular. The most popular numbers in passwords are: 1, 0, 2. Often somewhere in the middle are 3 and 9.
- The least popular numbers in passwords are: 7,6,8,5.
- Passwords very rarely use capital letters in any positions compared to lower case letters and numbers.
- Most popular letters in passwords are: a,e,i,o,n,r,s,l,t,m
- Lest popular letters in passwords are: q,x,v,w,j,z
Lets continue our exploration, maybe we will find something more. For example, how often do people use lower case letters, upper case letters, numbers and special symbols?
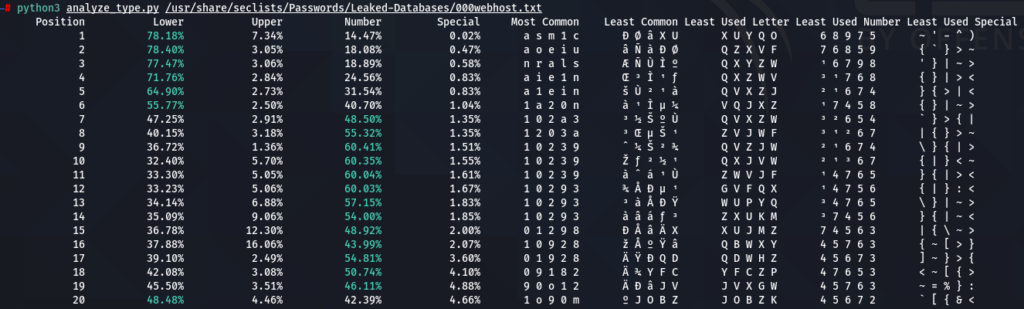
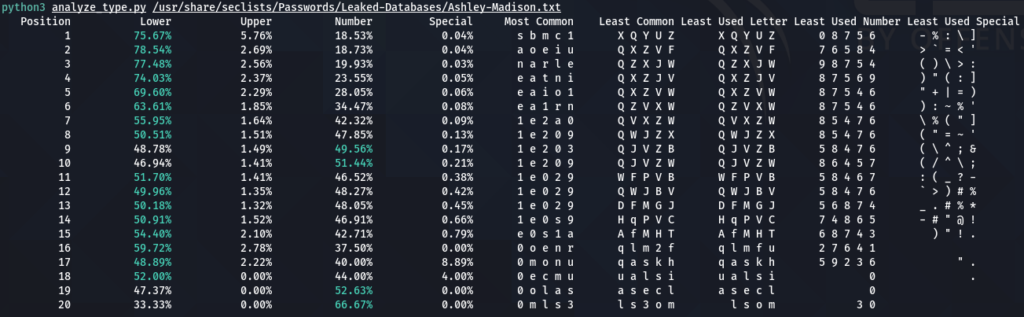
According to the data above, about nearly 75% are lower case letters, however, as we already saw, those numbers equalize with the rate of digits in passwords starting from 7-8th positions.
- We can also see the least common characters overall being X and Q, which is an interesting pattern.
- Lest used special symbols: Parentheses, curly brackets, vertical lines.
- Use of special symbols is most rare. From 0.02% to 1.5% for later positions. They are especially rare as the first character in passwords.
- Capital letters are rare too (although several times more frequent than special chars). And it is about twice as likely to see a capital character in the first position (about 5-7%) than in middle positions, with the slight increase at later positions.
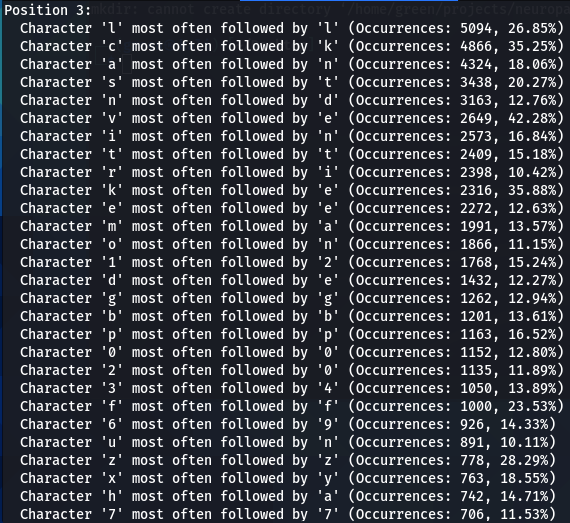
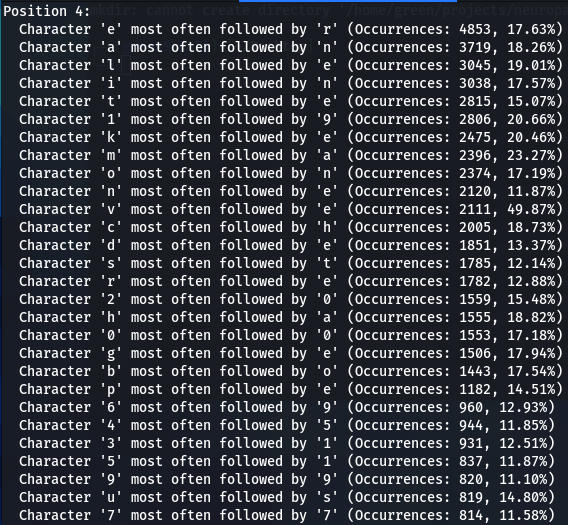
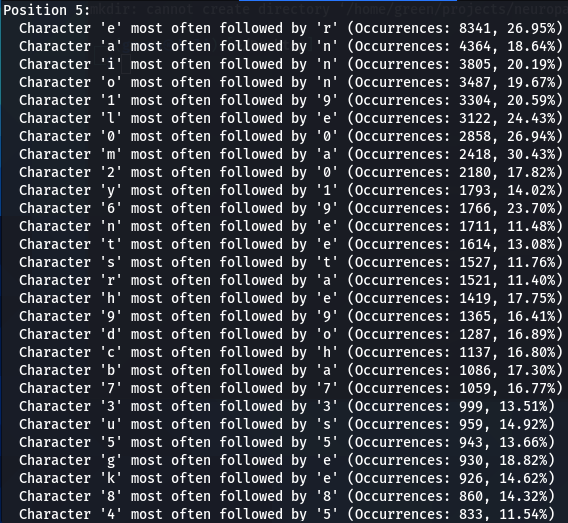
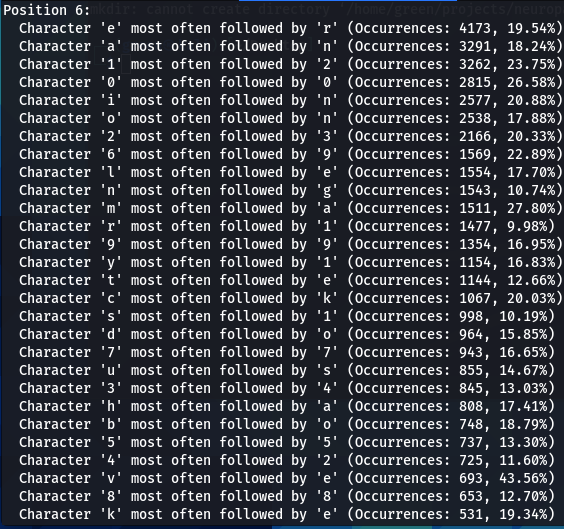
Now lets do a bit more comparative analysis. What characters are most often following other characters? For instance, which character is most commonly found after letter ‘a’? My next script was designed to calculate that.
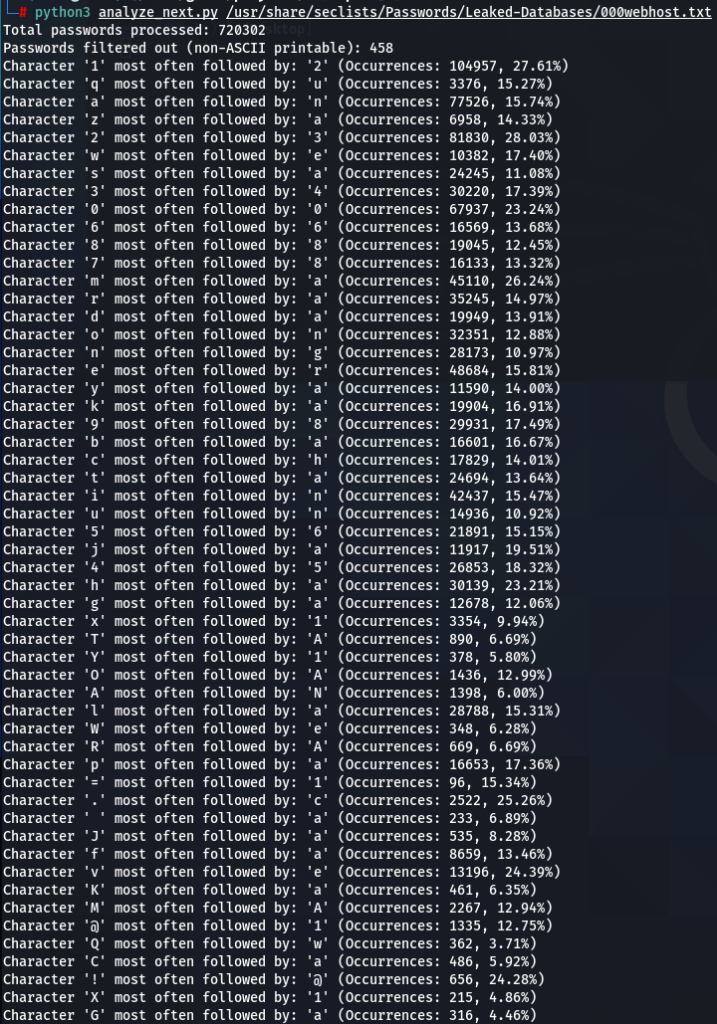
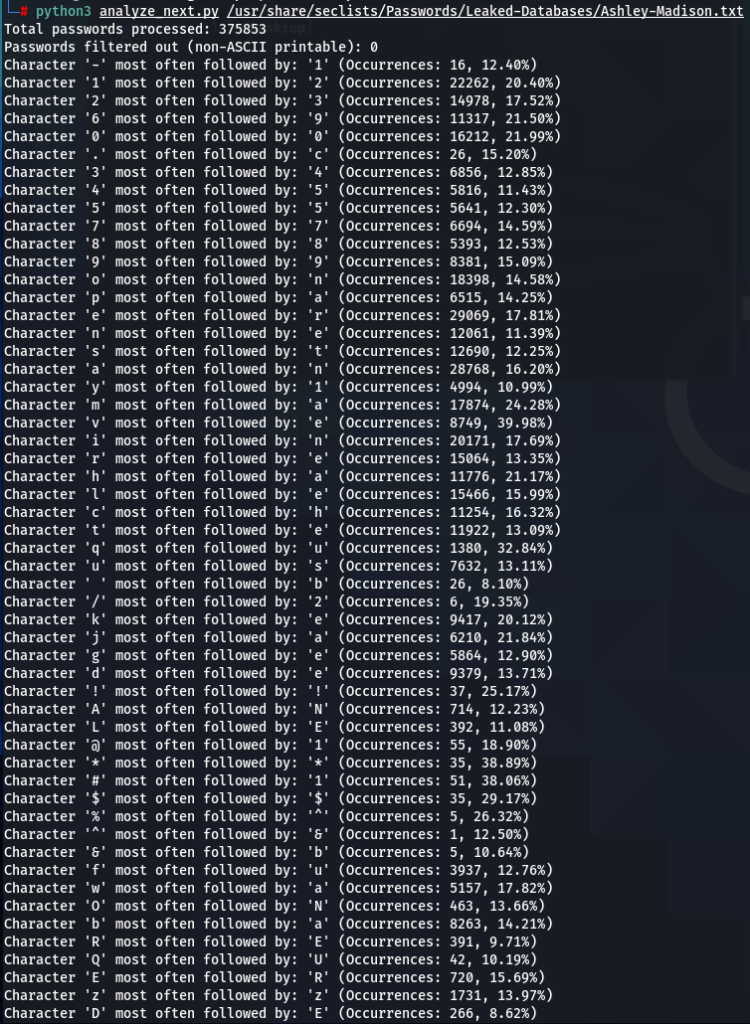
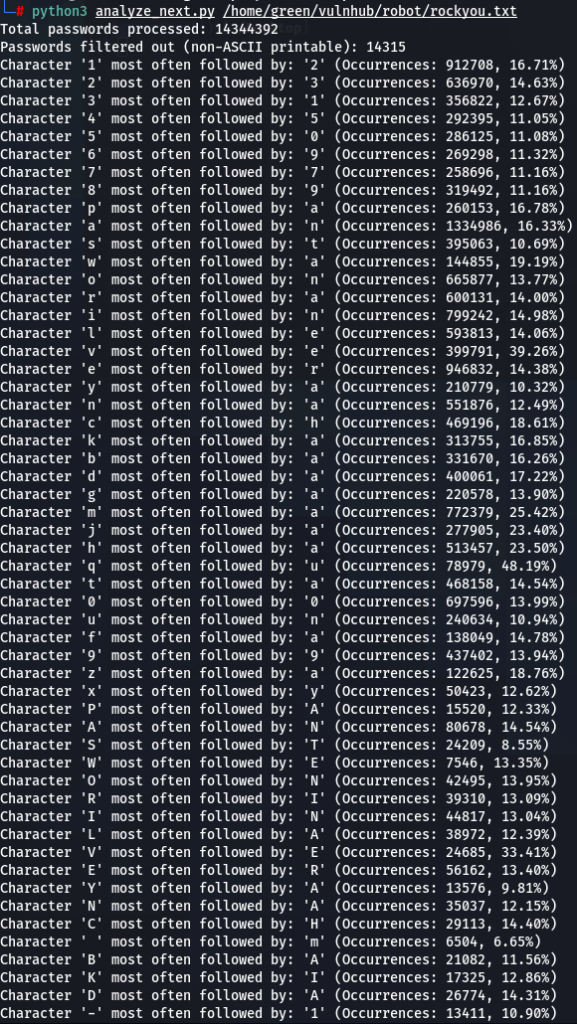
In addition to 000webhost and ashley-madison password wordlists, I also run the script on the major rockyou.txt. I noticed very similar patterns repeating in all three password datasets. For instance:
- Character ‘a’ most often follower by ‘n’
- Character ‘m’ most often follower by ‘a’
- Character ‘e’ most often follower by ‘r’, and so on..
The number of such patterns revealed is amazing. There seems to be a discernible preference for certain characters to follow others, indicating a pattern in how individuals sequentially choose characters when creating passwords.
And it shows another insight as to how a more intelligent bruteforcing tool could have operated.
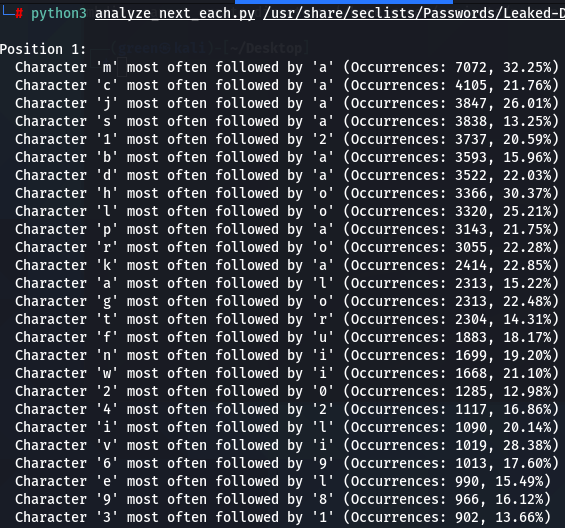
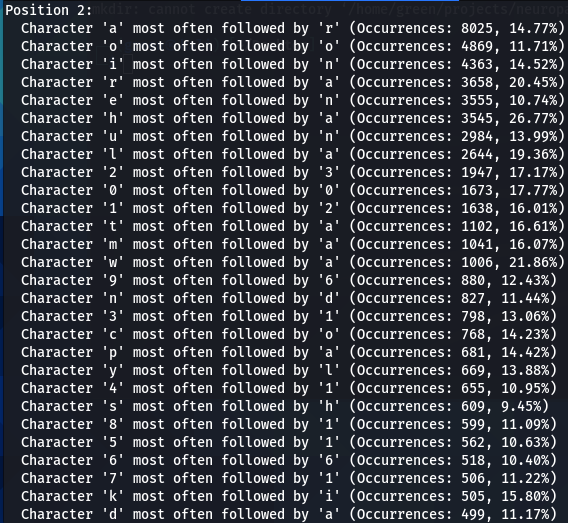
I began wondering if different patterns will emerge if the analyzed for each position separately, however, what I found out is that this pattern is rather position-independent. Note that in every case below (for Ashley-Madison dataset) ‘m’ is most followed by ‘a’, ‘a’ is most often (though always though) followed by ‘n’, and ‘e’ most often (but not always) followed by ‘r’. These patterns repeat with considerable consistency, thought with some variations.
Lets sum up some of the patterns we found throughout this research (they are not all, read the article for the more complete detailed info on all the patterns):
- Common Characters: The character ‘a’ frequently emerges as the most common across various positions, closely followed by ‘e’, ‘1’, ‘o’, ‘i’, ‘r’, and ‘s’. A notable precision is observed with some letters, like letter ‘d’ consistently appearing in the 16th position across multiple datasets.
- Initial Characters: While ‘a’ is generally the most common, ‘s’ dominates as the initial character in passwords, suggesting a strong preference for starting passwords with ‘s’.
- Second Position Dominance: The letter ‘a’ is exceptionally common at the second position, appearing as the most common character with approximately 16-18% occurrence, indicating one in every five passwords has ‘a’ as its second character.
- Numerical Shift: Analysis of large datasets reveals a shift towards the number ‘1’ as the most or one of the most common character from positions 6 or 7 through to the 14th, suggesting a mid-to-late password tendency towards numerical characters, especially ‘1’.
- Character Frequency Distribution: An intriguing cyclic pattern was discovered in character frequency distribution peaking at the 2nd position, dropping at the 3rd, and experiences a slight rise at the 4th position and then showing gradual decline towards later positions. This reflects a move from a small set of preferred characters to a broader, more random selection as the password lengthens.
- Specific Character Distributions: Many characters appear to show similar distribution frequencies across different datasets. For instance, the distribution of ‘s’ exhibits an interesting pattern, starting strong at the first position, dipping, and then rising again. This peculiar behavior might hint at underlying reasons such as vowel usage, keyboard placement, or commonality in English words.
- Numerical Prevalence: From the 6th position onwards, numbers become significantly more prevalent in passwords, with ‘1’, ‘0’, and ‘2’ being the most common. The least common numbers appear to be 6,7,5,8.
- Popularity and Rarity: While capital letters and special symbols are rarely used in passwords, the most popular letters include ‘a’, ‘e’, ‘i’, ‘o’, and ‘n’, with ‘q’, ‘x’, ‘v’, ‘w’, ‘j’, and ‘z’ being the least popular. The least common overall characters are ‘x’ and ‘q’, and the least used special symbols include parentheses and curly brackets.
- Character Succession Preferences: There is a clear pattern in character succession, such as ‘a’ often followed by ‘n’, indicating a pattern in sequential character choice when creating passwords.
This was part 2 of hidden patterns in passwords. In part 3 we will delve even deeper into this topic.